BeeGFS Hive Index¶
In today’s world where enormous amounts of data are generated every day, especially in supercomputing datacenters, querying and managing metadata about that data becomes very difficult as the scale of the data is so vast. For data management tasks like archival, scanning the filesystem to get the list of old files can impact the on-going filesystem operations. BeeGFS Hive Index helps to solve these problems efficiently by providing users with faster and more efficient access to their data and easy to use and highly performant interface and without impacting general filesystem operations.
BeeGFS Hive Index is a hierarchical metadata index created by extracting filesystem metadata and storing it efficiently in the local database. It provides the user a simple interface to query the index to get detailed metadata information, like file names, access/modification/creation time, permissions, file size, extended attributes and more.
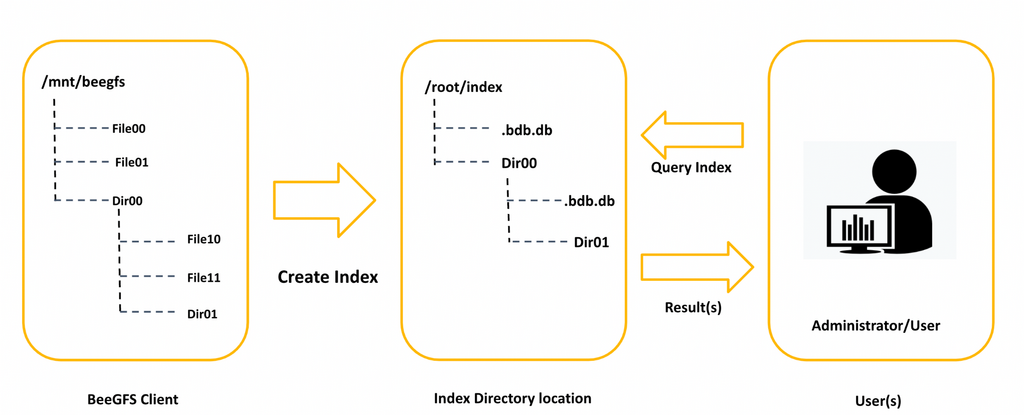
Description¶
BeeGFS Hive Index is a solution which allows users to quickly search through billions of files/directories and get the required information without impacting the filesystem performance. Its multithreaded design allows it to scan through multiple directories in parallel and extract the metadata efficiently. BeeGFS Hive Index supports POSIX user permissions, directory tree attributes and hierarchy representation.
Only the root user will be allowed to create the index as it has to scan through the complete directory hierarchy, and it may have directories/files from different users. So, it’s recommended to create an index by the administrator. Having a single index directory per BeeGFS Filesystem is better to keep it consistent with changing filesystem.
As the index maintains the user permissions, the index can be shared by all users and administrators. Even with a shared index, users are allowed to query only their own data.
There are two methods to create the BeeGFS Hive Index,
a different location (on another local filesystem) or within the BeeGFS.
In-Tree index¶
The index will be created inside the BeeGFS itself. Each subdirectory will have a .bdm.db database file containing metadata information specific to that subdirectory. Tables containing detailed metadata information about the files inside that directory (for example filename, timestamps, size, extended attributes, etc.).
The Disadvantages of creating an index inside BeeGFS are that it may interfere with on-going BeeGFS filesystem operations. If you want to keep the index data within BeeGFS, metadata scanning can be scheduled when there is little traffic on the filesystem.
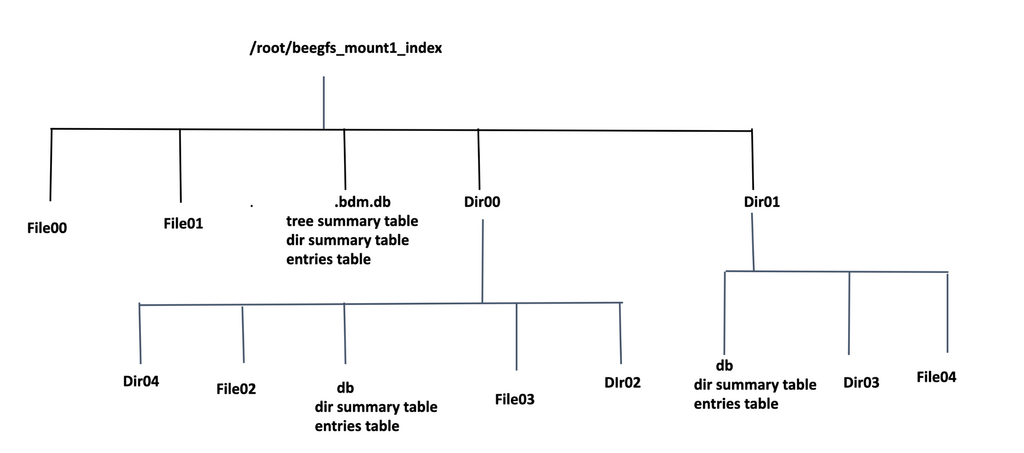
Out-Of-Tree Index¶
An Out-Of-Tree index allows users to create a filesystem index at a different location, (for example a local filesystem or an NFS share)
Index creation process will create a directory hierarchy structure similar to the source directory at the chosen index location. Each directory stores metadata information about its entries (files and subdirectories). The index directory hierarchy maintains the user permissions of the source directory and the hierarchical structure allows querying metadata faster.
BeeGFS metadata could be spread across multiple metadata nodes and querying the filesystem for administrative tasks can generate a lot of network messages which can interfere with user’s important operations.
As the Indexed data is stored on a local filesystem, querying the indexed metadata becomes really fast, and it does not interfere with filesystem important operations.
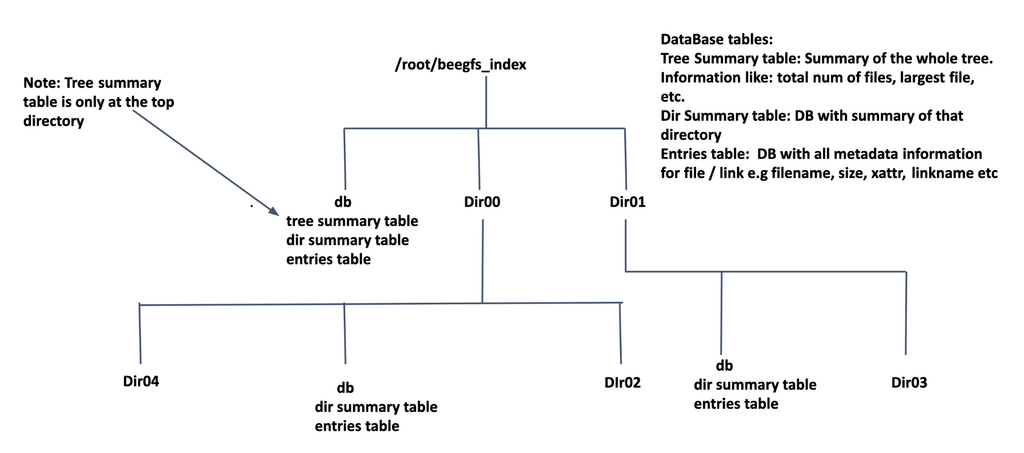
BeeGFS Hive Index Database¶
BeeGFS Hive index database (.bdm.db stored inside each subdirectory) holds three types of records as listed below:
- Entries Table: Stores detailed metadata information about files and
links (filename, size, blks, mtime, ctime, atime, extended attributes, etc).
- Directory Summary Table: Stores information like total files inside
the directory, total subdirectories inside the directory, total size of the directory (sum of all file’s sizes inside the directory) , etc.
- Tree Summary Table (optional): Stores a summary of the complete
directory hierarchy. This information is present only at the top level directory. The table contains information like total files in the directory tree, total subdirectories, maxfilesize, minfilesize.
Step-By-Step Guide for BeeGFS Hive Index¶
Prerequisites¶
The following packages need to be installed on the node that runs BeeGFS Hive Index:
libpcre3
libpcre3-dev
SQLite
python3
python3-distutils
Installation¶
RHEL based systems¶
BeeGFS Hive index repositories and packages are digitally signed. Add the public key to your package manager. This can be done as follows:
rpm --import https://www.beegfs.io/release/hive/gpg/GPG-KEY-hive
Download the BeeGFS Hive index package repository file for your distribution from BeeGFS Hive index package repository. eg. For RHEL 8 this can be done as follows.
wget https://www.beegfs.io/release/hive/dists/beegfs-hive-rhel8.repo -O /etc/yum.repos.d/beegfs_hive.repo
Install BeeGFS Hive index package.
yum install beegfs-hive-index
Debian based systems¶
BeeGFS Hive index repositories and packages are digitally signed. Add the public key to your package manager. This can be done as follows:
wget -q -O - https://www.beegfs.io/release/hive/gpg/GPG-KEY-hive | apt-key add -
Download the BeeGFS Hive index package repository file for your distribution from BeeGFS Hive index package repository. eg. For Debian 10 this can be done as follows.
wget https://www.beegfs.io/release/hive/dists/beegfs-hive-buster.list -O /etc/apt/sources.list.d/beegfs_hive.list
apt update
Install BeeGFS Hive index package.
apt install beegfs-hive-index
Initial configuration¶
BeeGFS Hive Index commands use a configuration file which must be present at
/etc/beegfs/index/config
A sample configuration file will be installed during the package
installation at /etc/beegfs/index/config.example which can be modified
and renamed to /etc/beegfs/index/config
Following are the important parameters from the config file:
# Number of threads for running index operations
Threads=10
Number of threads to run the Hive index commands. You should set this count as per the number of cores available on the system where the Hive index will be created.
# absolute path to bee executables
# single path string
Executable=/opt/beegfs
The absolute path where the BeeGFS Hive Index binaries are installed. Default
path is /opt/beegfs.
# Source directory path:Index directory path
IndexPaths=/mnt/beegfs:/mnt/index
Colon separated path to BeeGFS Filesystem directory for which index will be
created and absolute path for index directory. (Filesystem Source directory
path:Index directory path), for example IndexPaths=/mnt/beegfs:/work/index.
These two paths allow Hive Index commands to run without explicitly specifying absolute paths for source directory or Index directory.
If you want to create the index inside the filesystem directory itself, only
specify the source directory path in IndexPaths, for example
IndexPaths=/mnt/beegfs.
# Filesystem mount point path
MountPath=/mnt/beegfs
BeeGFS mount point.
BeeGFS Hive Index Utilities¶
All BeeGFS Hive Index operations can be performed through a single command called
bee which is generally installed to /opt/beegfs/python/index but will be
added to the standard PATH via symlink in /usr/bin.
Operations like creating an index, updating an index, listing the files from the
index and finding files from the index are the subcommands to bee.
BeeGFS Hive Index Creation¶
You can create an index using In-Tree (Inside Filesystem) or Out-Of-Tree(Outside filesystem) options as per the requirements.
For creating the index use the subcommand create-index.
Following are some of the important options to create-index.
-F : Filesystem directory path for which index will be created.
-I : Index directory path.
If -I is not provided and the config file does not have an index directory path specified,
the index will be created inside the filesystem directory itself.
-X : Maximum memory create-index operation should use e.g 8M, 12GB.
The index creation process scans through the entire directory hierarchy.
For really large filesystems, there can be a large number of files and directories
and large directory depth.
Users should set a limit on the memory that can be used during index creation to avoid memory
pressure on other applications running on the same machine.
-n : Number of threads which will be started for scanning directory hierarchy
and extracting and storing the metadata information. Specify this value looking
at the number of cores available for use during index creation.
Note
Both these options (-F/-I) are optional and default values will be taken from the configuration file (/etc/beegfs/index/config)
See also
man bee-create-index
[root@admin-compute1~]# bee create-index --help
usage: bee [--help] [-X MAX_MEMORY_USAGE] [-F FS_PATH] [-I INDEX_PATH]
[-n NUM_THREADS] [-s] [-x] [-z MAX_LEVEL] [-S] [--version]
BeeGFS Hive index version of create
optional arguments:
--help show this help message and exit
-X <MAX_MEMORY_USAGE> Max memory usage e.g 8M, 1G, 8GB, 16gb
-F <FS_PATH> File system path for which index will be created
-I <INDEX_PATH> Index directory path
-n <NUM_THREADS> Number of threads to create index
-s Create tree summary table along with other tables
-x Pull xattars from source
-z <MAX_LEVEL> Max level to go down
-S Create only tree summary table
--version, -v show program's version number and exit
Creating an In-Tree index¶
To create the index inside the filesystem itself, don’t specify index
path in the /etc/beegfs/index/config IndexPaths, for example:
IndexPaths=/mnt/beegfs
#Create index inside the filesystem
[root@admin-compute1~]# bee create-index
#If user wants to specifically mention the filesystem path
[root@admin-compute1~]# bee create-index -F /mnt/beegfs
#create in-tree index with tree summary table and memory limit 10GB and #4 threads
[root@admin-compute1~]# bee create-index -s -X 10GB -n 4
Creating an Out-Of-Tree Index¶
To create the index outside the filesystem, specify index path in the
/etc/beegfs/index/config IndexPaths, for example
IndexPaths=/mnt/beegfs:/work/index
/work/index could be a local filesystem or NFS shared directory.
If the config file has both filesystem source directory path and index path mentioned, bee create-index command will pick up the paths from config file.
#Create index outside the filesystem
[root@admin-compute1~]# bee create-index
#If user wants to specifically mention the filesystem and index paths
[root@admin-compute1~]# bee create-index -F /mnt/beegfs -I /work/index
#create in-tree index with tree summary table and memory limit 10G and #4 threads
[root@admin-compute1~]# bee create-index -s -X 10G -n 4
bee update¶
Note
The changes to beefgs-event listener needed to interface with bee update
are available in BeeGFS releases from versions 7.3.3 and 7.2.9.
The bee update subcommand allows users to update the index directory
with on-going operations. BeeGFS Hive Index uses modification events generated
by BeeGFS metadata nodes to update the index directory. BeeGFS’s event
listener captures the events generated on metadata nodes and sends it
over the network to the update service.
The modification logs from BeeGFS have the file path on which the operation is performed. bee-update service takes advantage of these events and modifies the Index directory for the specific file(s) or directories only. This mechanism avoids scanning the filesystem entirely to update the Index directory. And the index directory remains up-to-date with filesystem modifications.
Event listener should be started on all the metadata nodes so that all
filesystem operations can be captured and re-replayed on the index
directory by bee update.
For bee update to work, there should be an index created first using
bee create-index.
The bee update should run as a service to capture all on-going filesystem changes.
Users can run bee update from the command line or start it using systemctl.
To run using systemctl, update the configuration file
/etc/beegfs/index/updateEnv.conf
# updateEnv.conf
CMD_NAME=update
SRC_PATH=-F /mnt/beegfs
IDX_PATH=-I /work/index
MNT_POINT=-M /mnt/beegfs
PORT=-p 9000
DEBUG_MODE=-v 1
The update service should be started first and then the event listeners on all meta nodes.
# systemctl start bee-update
Following are the parameters for starting the bee update from the command line.
[root@admin-compute1~]# bee update --help
usage: bee [--help] -F FS_PATH [-I INDEX_PATH] [-M MNT_PATH] [-p PORT_NUM] [-v DEBUG_MODE]
BeeGFS Hive index version of update
optional arguments:
--help show this help message and exit
-F <FS_PATH> File system path for which index will be created
-I <INDEX_PATH> Index directory path
-M <MNT_PATH> File system mount point path
-p <PORT_NUM>, --port <PORT_NUM> port number to connect with client
-v <DEBUG_MODE>, --verbose <DEBUG_MODE> enable/disable bee update debugging by giving 1/0
beegfs-event-listener¶
Note
The changes to beefgs-event listener needed to interface with bee update
are available in BeeGFS releases from versions 7.3.3 and 7.2.9.
Metadata services must be configured to send filesystem modification events to the event listener. The event listener(s) on the meta node(s) can be started from the command line or using systemctl.
Update the configuration file for event listener
/etc/beegfs/beegfs-eventlistener.conf
# beegfs-eventlistener.conf
clientAddr=xxx.xxx.xxx.xxx
fileEventLogTarget = /tmp/beegfslog
updatePort=9000
BEE_UPDATE_DEBUG=1
The admin can configure which operations to capture from event listener by updating BeeGFS client config file:
sysFileEventLogMask = create,trunc,setattr,close,link-op,write
Also admin can configure metadata server and enable the event stream, by specifying path for the UNIX socket.
For example:
sysFileEventLogTarget = unix:/tmp/beegfslog
For more information, please check the BeeGFS event listener documentation for the same
See also
Once the update service is successfully started, start the event listener from all the meta nodes**. Starting event listener on all meta nodes is important otherwise index will not be updated correctly with the on-going operations. clientAddr is the IP address of the admin node on which index was created and bee-update service is running. And the updatePort is the port on which bee-update is listening for the filesystem updates.
# systemctl start beegfs-eventlistener
See also
man bee-update
bee stats¶
The stats subcommand allows users to obtain filesystem statistics
like the total number of files, directories or links in the directory hierarchy, files, directories, or links per level, maximum and minimum file sizes..
Note
bee stats should be run from Index directory or the Filesystem directory. We can also provide absolute path of directory.
e.g. bee stats total-dricount /work/index/arch/alpha or bee stats total-dricount /mnt/beegfs/arch/alpha
Some of the important options are:
1. total-filecount: Get the total number of files under a directory. It reports the count per uid. But with –cumulative shows cumulative numbers rather than per uid.
2. total-linkcount: Similar to total-filecount, gets the total number of links under a directory.
[root@admin-compute1~]# bee stats total-filecount
6980 1301
[root@admin-compute1~]# bee stats total-linkcount
2301 29
3. dirs-per-level/files-per-level/links-per-level: Get the count of <type>s in each directory level per uid.
[root@admin-compute1~]# bee stats files-per-level
root 0 14
root 1 801
root 2 11182
root 3 17738
[root@admin-compute1~]# bee stats dirs-per-level
root 0 1
root 1 19
root 2 468
root 3 1104
For other options please check the man page bee-stats
See also
man bee-stats
bee find¶
The find subcommand can be used to find the files in an index directory hierarchy.
find has very similar options to GNU find and allows users to get results
by running queries over the index directory.
Hive’s find is way faster than running actual find commands over the filesystem.
Following are some of the examples for bee find:
# Get the list of files which are greater than 1GB in size
[root@admin-compute1~]#bee find -size=+1G
/mnt/beegfs/dataset0/user1/test1.txt
/mnt/beegfs/dataset0/application.txt
/mnt/beegfs/dataset0/user2/test.txt
# Get the list of files which are created within 24 hours.
[root@admin-compute1~]#bee find -ctime=-1
/mnt/beegfs/dataset0/file.txt
# Get the list of files which are not accessed from the last 10 days.
[root@admin-compute1~]#bee find -atime=-10
/mnt/beegfs/dataset2/file1.txt
See also
man bee-find
bee ls¶
bee ls lists the index directory contents. It has similar options as standard ls commands.
bee ls can work with absolute paths and relative paths both. Run from index directory or filesystem directory
if running with relative paths.
Following are some of the options for bee ls.
# Print the inode number of the files in a directory
[root@admin-compute1~]# bee ls -i user/data/
3224807882485797791 core.c
9553679804207926350 kfence.h
10232643267511233810 kfence_test.c
16487850910921490669 Makefile
348824457185005735 report.c
# Sort the files in a directory in descending order and print the size.
[root@admin-compute1~]# bee ls arch/alpha/boot/ -Ss
27 bootpz.c
13 stdio.c
12 bootp.c
9 misc.c
# List the files in a directory with sizes in human readable format.
[root@admin-compute1~]# bee ls -hls
1 -rw-rw-r-- 1 root root 496.0 Feb 11 08:26 COPYING
198 -rw-rw-r-- 1 root root 98.6K Feb 11 08:26 CREDITS
1 drwxrwxr-x 4 root root 144.0 Feb 11 08:26 data
1 drwxrwxr-x 81 root root 97.0 Feb 11 08:26 Documentation
See also
man bee-ls
bee stat¶
bee stat displays file and directory metadata information. It has similar options as GNU stat.
bee stat can be run with the absolute path of the filesystem or index directory from anywhere.
To use relative paths, bee stat commands should be run from inside a filesystem source directory or index
directory.
[root@admin-compute1~]# bee stat README
File: '/dataset/index/README'
Size: 727 Blocks: 2 IO Block: 524288 regular file
Device: h/ d Inode: 8523084679231612220 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context:
Access: 2023-01-03 09:09:48 +0100
Modify: 2022-02-11 09:26:32 +0100
Change: 2023-01-03 09:09:48 +0100
Birth:
See also
man bee-stat
bee query¶
bee query subcommand allows users to execute SQL queries directly over the index database.
This command can be useful if users want to get specific metadata information which is not accessible using the Hive Index commands.
[root@admin-compute1~]# bee query-index --help
usage: bee [--help] [-I DB_PATH] [-s SQL_QUERY]
BeeGFS Hive index version of query-index
optional arguments:
--help show this help message and exit
-I <DB_PATH> Index directory path
-s <SQL_QUERY> Provide sql query
List the database entries for files inside net directory
[root@admin-compute1~]# bee query-index -I net/ -s "select * from entries"
|id|name|type|inode|mode|nlink|uid|gid|size|blksize|blocks|atime|mtime|ctime|linkname|xattrs|crtime|
|ossint1|ossint2|ossint3|ossint4|osstext1|osstext2|
|1|devres.c|f|14759502047005719714|33204|1|0|0|2250|524288|5|1672733465|1644567992|1672733465|||0|0|0|0|0|||
|2|socket.c|f|11365958989076786435|33204|1|0|0|89444|524288|175|1672733467|1644567992|1672733467|||0|0|0|0|0|||
Get the summary information for net directory
[root@admin-compute1~]#bee query-index -I net/ -s "select * from summary"
|id|name|type|inode|mode|nlink|uid|gid|size|blksize|blocks|atime|mtime|ctime|linkname|xattrs|totfiles|totlinks|minuid|maxuid|
|mingid|maxgid|minsize|maxsize|totltk|totmtk|totltm|totmtm|totmtg|totmtt|totsize|minctime|maxctime|minmtime|maxmtime|minatime|
|maxatime|minblocks|maxblocks|totxattr|depth|mincrtime|maxcrtime|minossint1|maxossint1|totossint1|minossint2|maxossint2|
|totossint2|minossint3|maxossint3|totossint3|minossint4|maxossint4|totossint4|rectype|pinode|
|1|net|d|5920216113766933286|16893|72|0|0|76|524288|1|1672733464|1644567992|1672733467|||6|0|0|0|0|0|2250|89444|0|6|6|0|0|0|126954|1672733464|1672733467|
|1644567992|1644567992|1672733464|167273|3467|5|175|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|10872060183036577154|
See also
man bee-query-index
Limitations and Known Issues¶
Index creation process scans through the filesystem directory and captures the metadata information. If any modifications happen after the directory was scanned, create-index process cannot capture those modifications and index would not have exact same state as filesystem. BeeGFS hive index do not apply the modification events while create-index is in progress. Creating index on the idle filesystem makes sure all the metadata is captured properly and index has up to date information.
Index update works on the already created index. Index could miss some filesystem modification update if bee-update service is not started immediately after the filesystem scan.
Index is updated using modification events captured on metadata nodes by event-listener service. These events are sent over the network from metadata nodes to the bee-update service. Due to potential network disconnects, the bee-update process might miss some filesystem modification events which can cause the index to go out of sync.
The modification events from event listener provide the file/directory path and operation type but do not provide information about changed metadata. For example, for a truncate modification event, the new file size. bee-update needs to get the modified metadata again from the filesystem, i.e. via a
stat()operation, to update the index.
Potential Future Enhancements¶
Modification events generated by a metadata node could also include the modified metadata e.g. file size, timestamps, etc. other than path name. With this metadata information, bee-update wouldn’t have to send a request to the filesystem to update the index.
To make sure index remains in sync with filesystem state, allow create-index and bee-update to run simultaneously.
Event listener could buffer modification events when it is not able to send them to bee-update immediately. This would solve the issues of potential loss of events in case of high load on the metas or network disconnects.