BeeOND: BeeGFS On Demand¶
What is BeeOND?¶
BeeOND (”BeeGFS On Demand”, pronounced like the word “beyond”) was developed to enable easy creation of one or multiple BeeGFS instances on the fly. This ability can be useful in many different use-cases, for example, in cloud environments, but especially to create temporary work file systems. BeeOND is typically used to aggregate the performance and capacity of internal SSDs or hard disks in compute nodes for the duration of a compute job. This provides additional performance and a very elegant way of burst buffering.
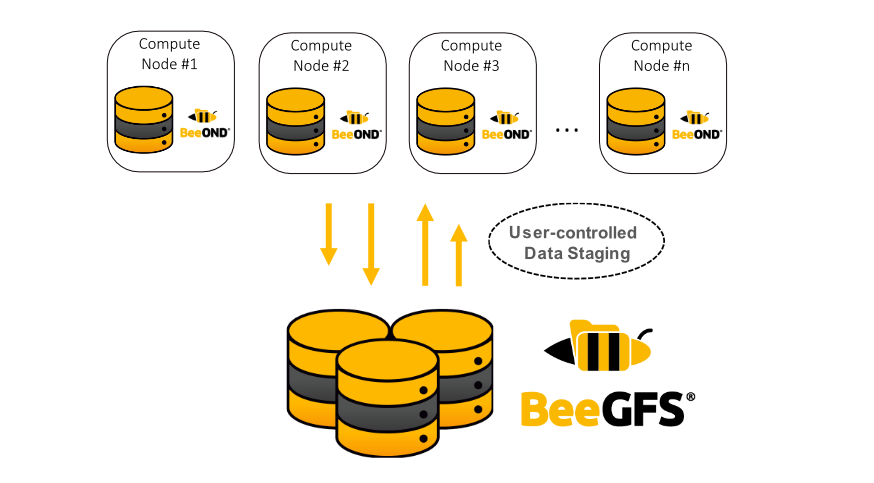
Most HPC cluster systems use a global storage system based on a parallel file system on dedicated servers to enable high throughput. Compute nodes are often equipped (or can easily be equipped) with internal hard disks or SSDs, which could deliver an additional performance advantage. The problem with the internal drives in compute nodes is that they provide neither the advantage of a single name space across multiple machines nor the flexibility and performance of a shared parallel file system. BeeOND solves this problem by creating a shared parallel filesystem on a “per-job basis” across all compute nodes that are part of the particular compute job, exactly for the runtime of the job.
BeeOND can be used independent of whether the global shared cluster file system is based on BeeGFS
or on other technology. BeeOND simply creates a new separate mountpoint. Any of the standard tools
(like cp or rsync) can be used to transfer data into and out of BeeOND, but the BeeOND
package also contains a parallel copy tool to transfer data between BeeOND instances and another
file system, such as your persitent global BeeGFS.
Due to the very simplified startup, it is easy to integrate BeeOND with workload managers, such as Torque or Slurm. Torque, for example, provides prologue and epilogue scripts, which will be executed on the first node assigned to a job. As BeeOND can start and stop new BeeGFS instances with just one single command, you can easily add it to these scripts to start BeeOND when a compute job starts and stop it when the job is finished. Please refer to the documentation of your workload manager for similar mechanisms.
Advantages¶
The main advantages of the typical BeeOND use-case on compute nodes are:
A very easy way to remove I/O load and nasty I/O patterns from your persistent global file system. Temporary data created during the job runtime will never need to be moved to your global persistent file system, anyways. But even the data that should be preserved after the job end might be better stored to a BeeOND instance initially and then at the end can be copied to the persistent global storage completely sequentially in large chunks for maximum bandwidth.
Applications that run on BeeOND do not “disturb” other users of the global parallel file system and in turn also got the performance of the BeeOND drives exclusively for themselves without any influence by other users.
Applications can complete faster, because with BeeOND, they can be running on SSDs or a RAM-disk, while they might only be running on spinning disks on your normal persistent global file system. Combining the SSDs of multiple compute nodes not only gets you to high bandwidth easily, it also gets you to a system that can handle very high IOPS.
BeeOND does not add any costs for new servers, because you are simply using the compute nodes that you already have.
You are turning the internal compute node drives, which might otherwise be useless for many distributed applications, into a shared parallel file system, which can easily be used for distributed applications.
You get an easy chance to benefit from BeeGFS, even though your persistent global file system might not be based on BeeGFS.
Installation¶
BeeOND is available as a standard package in the normal BeeGFS repositories and can be installed by
using your distribution’s package manager. For example, if running Red Hat, you can simply use
yum on all nodes in your cluster:
$ ssh root@nodeXX
$ yum install beeond
For operation, BeeOND needs the BeeGFS server and client components. Therefore, the respective packages are set as dependency and will be installed automatically.
Note
The BeeOND package needs to be installed on all hosts that are part of the BeeOND instance.
Usage¶
The main component of the BeeOND package is a script to start and stop a BeeGFS file system
instance. This script is located at /opt/beegfs/sbin/beeond. A BeeOND instance can be controlled
using “beeond start” and “beeond stop”.
The easiest way to start a BeeOND instance is running beeond with the following set of parameters:
$ beeond start -n nodefile -d /data/beeond -c /mnt/beeond
Description of start parameters:
nodefileA file containing all hostnames to run BeeOND on (one host per line). All hosts in this file will become clients and servers for this new file system instance.
/data/beeondShould be substituted with a path, in which BeeOND will save its raw data on each node.
/mnt/beeondShould be substituted with the path where the BeeOND instance shall be mounted on each node.
To shut a BeeOND instance down, you only need to use the “stop” mode of the script, similar to startup:
$ beeond stop -n nodefile -L -d
Description of stop parameters:
nodefileA file containing all hostnames that were used on the startup of the BeeOND instance.
-LDeletes all log files that were created by this BeeOND instance.
-dDeletes the raw data that was written by this BeeOND instance.
For more detailed information and additional parameters, please see:
$ beeond -h
Storage pools¶
BeeOND supports the utilization of storage pools. It is able to automatically create multiple targets on all involved hosts and assigns them to pools.
To use pools, a target configuration file has to be created. It needs to be in the following format:
pool_1:/path/to/target_1,/path/to/target_2,...
pool_2:/path/to/target_3,/path/to/target_4,...
...
Supply this file to BeeOND with the -t option. Each line corresponds to one pool. The name of
the pool is placed at the beginning of the line. This name will also be used for the pool directory.
After the colon, a list of target paths with at least one target must be supplied. The list
(including the paths itself) can’t contain white-space characters. BeeOND will look for these
directories and add them as a storage target to the corresponding pool on all nodes where they
exist. To avoid having unwanted targets in a pool, make sure each of the specified paths only exists
on nodes where they are actually mounted on the desired storage medium. BeeOND will create a
directory on the top level of the BeeGFS mount, named after the pool name, that is set to use the
corresponding storage pool (unless -T is specified).
The storage pool option has to be used together with -F, because reusing old data does not work
together with pool creation and assignment.
Additional Tools¶
To use the beegfs-ctl command line tool with BeeOND instances, you can use the BeeOND mountpoint
(--mount) as an argument. To list the registered storage nodes of a BeeOND instance, the command
would look like this:
$ beegfs-ctl --mount=/mnt/beeond --listnodes --nodetype=storage
The tool “beeond-cp” can be used to perform a parallel stage-in and stage-out of the data you
need. If we assume, that you need two working sets, which are located in /scratch/first and
/scratch/second you can use the following command to copy the data into /mnt/beeond:
$ beeond-cp copy -n nodefile /projects/dataset01 /projects/dataset02 /mnt/beeond
Description of copy parameters:
nodefileA file containing all hostnames to run the distributed copy on (typically the same nodefile that was used for “beeond start”).
/projects/dataset01and/projects/dataset02The source directories to be copied (you can use one or multiple files or directories as a source here).
/mnt/beeondThe target directory for the parallel copy.
For a more detailed information, please see:
$ beeond-cp -h